|
Peano
|
|
Peano
|
This is my favourite starting point for data if I'm interested in whole movies and not only particular snapshots. Yet, it might become inconvenient for large datasets, as it is too slow.
The command line, Python-based conversion of Peano works if and only if you have Paraview plus Python installed. First, ensure Peano's visulisation component is in your Python path:
export PYTHONPATH=Peano-dir/python
and consult the remarks on third party software for further troubleshooting if there are further issues.
After that, use the conversion script there to translate your peano-patch-file. It is important that you interpret this script through pvpython:
pvpython Peano-dir/python/peano4/visualisation/render.py --help
You should see a usage message now. The API comes along with all kind of filters and stuff (you can for example filter out coarse grid data, which is something I'd recommend, or you can rescale individual patches).
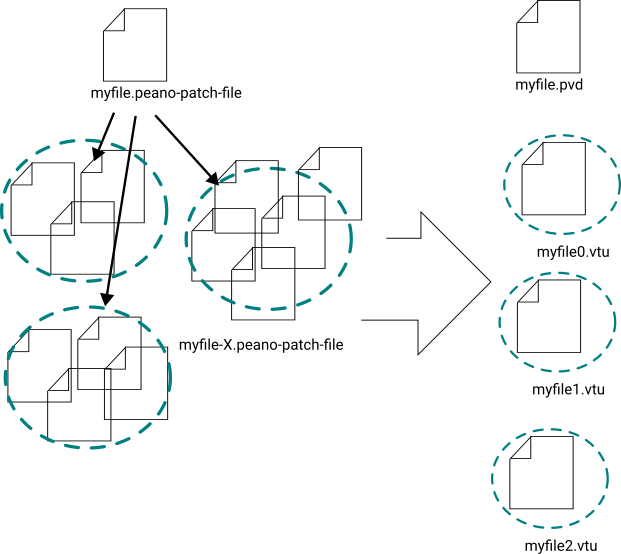
Peano applications dump their data into peano-patch-file files. These files in turn can include other files. Usually, you have one top-level file, and then this file references multiple files per time step - typically one file per subpartition per time step. The convert tools fuses all snapshots per time step and glues them together into one huge vtu file. On top of this, it generates (unless told otherwise) a pvd file which is really only an index over the vtu files and allows you to load all of them as one video within Paraview.
Please note that this variant to convert data requires you to install Paraview with Python. This is now the default if you install Paraview on your Linux distribution. We have however seen several cases where container images do not ship Paraview with Python. In this case, you might have to install it manually (or leave the container for the conversion).
Installing Peano's VTK command line tools can be quite tricky - depending on your local VTK installation. At the same time, the command line conversion via executables, i.e. not via the Python terminal as discussed above, is by far the fastest route. It can even exploit multiple cores. I recommend to stick to the Python-based postprocessing route as long as possible and to switch to the offline postprocessing only for large-scale production data where Python is just too slow and/or all postprocessing has to happen on a remote supercomputer as you cannot transfer the (raw) Peano data files.
If you configure with VTK support, Peano builds a command-line tool convert which you can use to convert 's patch files into plain (binary) vtk.
Installing VTK support can be challenging. Here's some things you might want to consider/check:
export LDFLAGS="-L/opt/vtk/lib64"
Once you have managed to configure with VTK and the build process has terminated successfully, your directory src/convert holds the actual convert script. If you call convert without arguments, you get a usage message. convert allows you to extract data from a data dump, and store it within the patch files under a new identifier. It also allows you to extract a dataset from patch files into vtu. vtu is one of VTK's binary file formats.
A standard postprocessing workflow on the command line reads as follows:
Unfortunately, our C++ conversion kernels do not offer all the functionality we now find within the Python-based tools. Things alike mesh distortion are missing here.